..or why using them is still a good idea⚓
Distribution packages⚓
Software and it’s dependencies maintained by Linux distribution vendor (Debian community, Canonical, RedHat, etc.), delivered by packages (DEB, RPM, ..) usually provided using package repositories (packages are signed so their authenticity is verified on download).
These packages actually forms stable Linux distribution because they are tested altogether. Especially Debian has great CI infrastructure where packaged software can be tested in case of dependency update.
As an example, let’s take Python application which doesn’t have much dependencies and generate dependency graph:
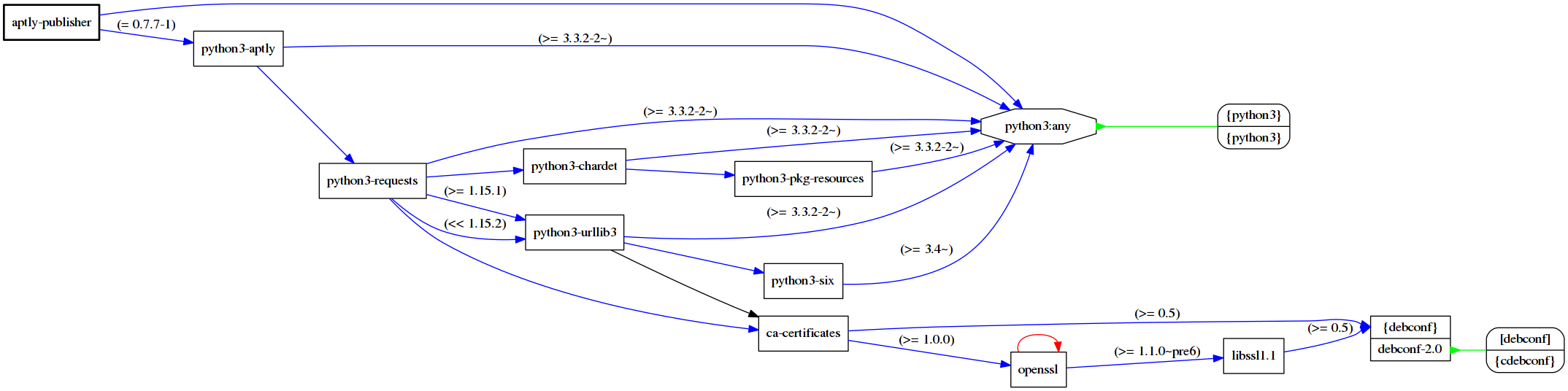
As you can see, you never deliver just application, you always deliver at least some dependencies, dependencies of dependencies and so on, including essential C libraries (eg. libssl in this example).
If anyone tells you that Docker is only about installing and running single application and base distribution doesn’t matter.. don’t belive it as he’s only another naive utopist :-)
At the moment there’s 860 packages in Debian repositories which directly depends on libssl and 404 packages which depends on python-requests.
And distribution maintainers and developers are here to ensure that update of libraries like python-requests or libssl won’t break anything. Beside of that they are taking care of distribution purity, ensuring that every package has documentation, every binary has a man page, that copyright and license file is in place and that user understands what he is going to install. Again, especially Debian is very strict on this and has great set of pedantic tests to ensure everything is correct. Check resources at https://qa.debian.org, especially https://lintian.debian.org if you don’t belive me :-)
Cons⚓
Now to the bad things..
- There is and will always be software which is not packaged for your
distribution
- so yes, you need to teach people how to make packages
- and have some CI and repository management
- Stable version of your distribution means older versions of software
- but you can run Debian testing or unstable which contains up-to-date software and this can be especially useful in Docker world where you can build image based on debian:unstable running just single up-to-date application
- or you can use your CI and repository management to make backports, that way you are basically creating your own Linux distribution
- Distribution vendors also make mistakes
- so their minor update of single package can ruin your environment
- sometimes you need to fix something and don’t wait for upstream
- so again, you need your own repository management and testing
- Sometimes you need to run multiple versions (or series) of some software
- this can be done by repository components (eg. by OpenStack release - kilo, liberty, mitaka)
- or by prefix in package names (eg. python-, python3-)
Docker⚓
First of all it’s not true that container == Docker. Containers existed sooner than Docker (eg. LXC, OpenVZ) and was about running OS userspace (so using host’s kernel) in very lightweight sort-of virtualization (far comparable with Xen paravirtualization).
Then came docker with tooling and essential thoughts about container management:
- isolation done by facilities provided by Linux kernel - cgroups and namespaces, similar as LXC does
- images built using Dockerfile, distributed using private Docker registry or public Dockerhub
- container should run single application
This application focus brings many advantages over VM world:
- complete isolation of individual pieces (applications)
- much faster deployment (images are just ready to go)
- easier rolling updates and management (scaling up/down, updating by spinning up new containers and just re-routing traffic and many new easy-to-be-done options)
The biggest deal (beside of orchestration of containers deployment which can be solved by tools like Kubernetes, Docker Swarm, etc.) which we are going to talk about is creation of Docker images.
Most Dockerfiles are similar to shell scripts, with structure like this:
- use base debian/centos/whatever image
- setup additional repositories if needed
- install Python, Go or programming language of one’s choice
- install software using Pip or whatever management one’s programming language offers
- define entrypoint - application binary itself or shell script as a wrapper
that will for example:
- generate configuration file using ENV variables it obtained on container launch (eg. mysql root password)
- do whatever preparations app needs to run (eg. create missing directories on volume)
- finally launch application
Does it remind you something? Déjà vu or maybe some scary memories of childhood? Didn’t we already solve this once using configuration management.. SaltStack, Puppet, Ansible? Why are we going to make a step backward to shell scripts?
Fortunately it’s possible to do this using your existing configuration management, see for example docker-salt project but back to our topic.
That way, developers can create docker images easily, in similar manner they are using for example Python’s virtualenvs for local development. They can install anything, any version in any way, no restrictions. A dev’s paradise. And they can upload final image so anyone can download and use it and it will work just in the same way.
But experienced sysadmin will surely ask some questions:
- base image is comming from Dockerhub - who made that image, is it trustworthy? Is it cryptographically signed and signature verified on download?
- core libraries (Python, dev libraries, possibly more) are comming from upstream distribution - how do I quickly patch all images in case of critical security issue in libssl?
- application and it’s dependencies are comming from Pypi - again, is it trustworthy source? Are all these packages signed and signature verified?
- how can I be sure that critical security issue in dependency (eg. urllib) is fixed and developers just didn’t blindly lock it’s version using requirements.txt?
- now we need to maintain multiple completely different ecosystems in case we are going to keep some “legacy” environments running VMs/bare-metal
And surely he will never deploy image from public dockerhub into production to avoid ending up like when Hitler uses Docker :-)
So it’s clear there must be rules and defined workflows. Docker isn’t package management tool - most people think they will just replace distribution packages by Docker but they will replace well-tested stable, security updated distribution packages by something similar to curl install.sh | sudo bash
But fortunately there’s a solution - let Docker be revolutionary for developer use but take it evolutionary for production. Keep using distribution packages and just extend your workflows and repository management to cover build of docker images.
It will bring following advantages:
- Repository management remains source of truth for versions going to be
installed
- when it’s snapshot or environment-based you can always return to stable set of packages, alter only versions you need (eg. security fixes)
- keeps still the same testing and QA process (on repository level), just extending it to use Docker images for infrastructure testing
- Image builds are reproducable (per-environment repository locks versions) so you can make a small change in image without risk of being stucked on new version of upstream dependency, breaking up your app
- By image creation date and snapshot of repository, you can easily tell which images needs update after critical security fix of package xyz
- Build entirely from secure, trusted source (image build should have no Internet access except for package repository, which is rule that applies for package builds as well)
Repository management⚓
So my advice is to have Repository management as a core component of all your workflows.
For Debian, you can use Aptly, for RHEL-based distributions there’s Pulp which works in a very similar way.
Simple workflow can consist of 3 environments (but there can be more depending on company’s use-cases).
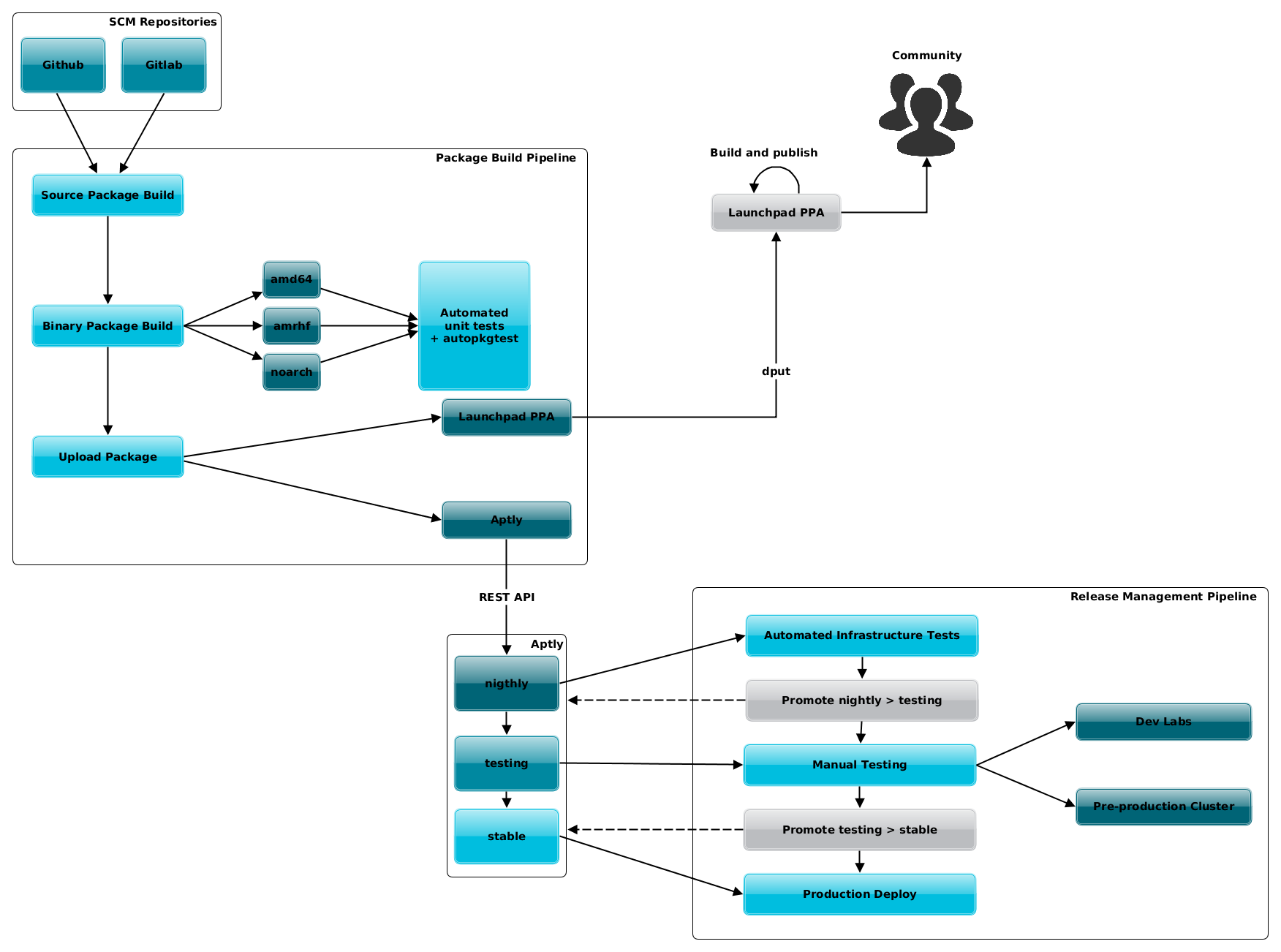
- nightly
- up-to-date mirrors of upstream and 3rd party APT repositories
- latest builds of your packages
- automated integration tests run against this environment
- nightly builds of docker images
- testing
- promoted packages from nightly that passed automated testing
- base for staging environments where manual testing is done
- testing builds of docker images
- stable
- source for production updates and build of production docker images
- QA approves promotion from testing
- stable builds of docker images
This workflow covers packages from all sources:
- upstream distribution packages (eg. mirror of Debian repository)
- 3rd party repositories (various Launchpad PPAs, 3rd party vendors)
- custom packages including:
- company’s software
- additional packages
- backports and fixes of upstream packages
When using Aptly, you can automate these workflows using it’s REST API. This can be done by re-using aptly-publisher which is CLI tool for management of Aptly publishes and designed for workflows similar to one described in these paragraphs.
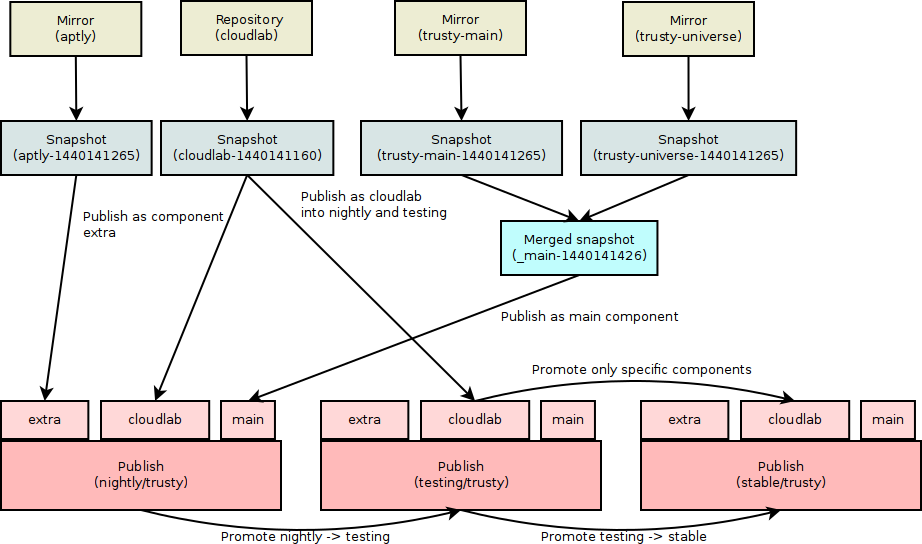
This way, your private Docker registry will always reflect state of your packages repository. You can always deploy up-to-date myimage:stable or you can apt-get install myapp on VM or bare-metal and you will get the same result. You are still maintaining software in the same way for all ecosystems (no matter if it’s container, Docker, VM or bare-metal) as you did before but wich much easier deployment and integration testing thanks to advantages of Docker.